Peter M. W. Robinson "New methods of Editing, Exploring, and Reading The Canterbury Tales": Based on a talk given at the conference ‘I nuovi orizzonti della filologia', Accademia Nazionale dei Lincei, Rome, May 28 1998
Quick links to subsections:
Introduction
Geoffrey Chaucer's The Canterbury Tales presents one of the most difficult textual problems in all of English Literature. The work was left unfinished at Chaucer's death in 1400, and survives in some 88 versions dating before 1500. Of these 84 are manuscripts, four are early printed editions, and around sixty are relatively complete, with the others being more or less fragmentary. Six hundred years of scribal and editorial activity has been unable to resolve fundamental questions relating to the text of the Tales. Exactly what did Chaucer leave behind him at his death? How unfinished are the Tales? Did he prepare a fair copy of all, or any part, of the Tales before his death? Did he issue any separate parts of the Tales in his lifetime, and do any of the extant versions descend from these separate publications? Which of the surviving versions is nearest to what Chaucer actually wrote? Did Chaucer revise the text of the Tales, and do the differences between the surviving versions reflect, to some extent, Chaucer's revisions of his own text?
Previous scholarship
Many scholars have attempted answers to these questions. The most elaborate attempt was that of John Manly and Edith Rickert. In the 1920s and 1930s they identified every version of the Tales, gathered copies of them, compared them word by word on some 60,000 collation cards, analyzed the tradition on the basis of this collation, and finally, in 1941, published an edition based on all this information. Fifty years on, it has to be said that Manly and Rickert's work was a failure. No-one uses their edition; their presentation of evidence and conclusions is obscure and often incomprehensible; their methods have been vigorously attacked. Further, their failure has had a most unfortunate effect: it appears to have led scholars to presume that the questions surrounding the text of The Canterbury Tales are so difficult that it is not worth even asking them. This has led to a curious situation in Middle English scholarship. In the last thirty years, great scholarly attention has been paid to the text of Langland's Piers Plowman. Yet there has been hardly any study of the text of The Canterbury Tales, a far greater work with far greater textual problems.
The origins of The Canterbury Tales Project lie in the perception that the advent of computer technology offers new methods, which might help us ask these questions in a new and more fruitful manner. In addition, electronic publication would let us not just ask these questions: it would let us present all the materials to the reader, and allow us to supply the reader with the tools to ask these same questions, and so test our conclusions. We can now put all the manuscripts, all the texts, all the tools, onto a single CD-ROM, or onto the computer networks. Above all, computer technology offers us this challenge: how can we use all these methods to help the reader?
The Canterbury Tales Project
The beginnings of the project were in 1989 with an experiment, funded by the Leverhulme Trust, using manuscripts of part of the Tales to test the collation program I was then developing. In 1991, Elizabeth Solopova began work on preparing these materials for the computer. The real commencement of the project may be said to have been a meeting in 1992 between myself and Professor Norman Blake of the University of Sheffield. Blake is one of the few scholars who, over the last decades, has broken the scholarly silence on the text of the Tales, and his direction of the project since 1992 has been crucial. At this time, Blake, Solopova and myself established the methods of the project:
- We would establish a system of transcription for all the manuscripts into computer-readable form
- We would transcribe the manuscripts using this system
- We would compare all the manuscripts, creating a record of their agreements and disagreements with a computer collation program
- We would use computer-based methods to help reconstruct the history of the text from this record of agreements and disagreements
- We would publish all the materials, the results of our analysis, and the tools which we use in electronic form.
We have now completed the first four of these stages for the 58 manuscripts and early printed editions of The Wife of Bath's Prologue. The transcriptions, collations, and images of these were published on CD-ROM by Cambridge University Press in 1996, and I will show something of this later. The analysis was published in printed form in the second volume of our Occasional Papers series, in 1997. Later this year, we will publish our second CD-ROM, that of The General Prologue (edited by Elizabeth Solopova). We expect that this will complete the fifth stage: we will publish on this the tools we have used to analyze the tradition.
Let us now look at each of these stages in detail.
The system of transcription
This is described in an article by Solopova and myself, 'Guidelines for the Transcription of Manuscripts of The Wife of Bath’s Prologue’ in our first Occasional Papers volume; this article is also reproduced on the Wife of Bath CD-ROM. We determined to aim at an original-spelling (or: graphemic, or diplomatic) transcription. Thus, our transcripts would record all possibly-significant spellings in the witnesses. In the case of abbreviations, then, we would not expand the abbreviation but would record the actual mark of discrimination. We would also record certain features of the text's presentation (the use of decorated capitals, underlining, or other emphatic marking) and all scribal additions and deletions. Further, we would mark each line of text, to enable the computer to find and collate each distinct line.
Armed with these principles, we began to transcribe the manuscripts. Here is an image of the first lines of the General Prologue as it appears in the Christ Church, Oxford, manuscript:
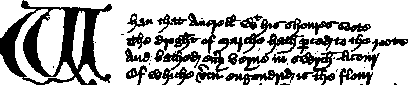
Figure 1: the opening lines of The General Prologue, from Christ Church, Oxford, MS 152
Here is our transcription of these lines:

Figure 2: our transcription of these lines
You will see here how far we have gone in trying to preserve all the detail of the spelling of the manuscript. We have recorded all the abbreviations, in 'with' and 'pereced'. We have recorded the possible abbreviation of final -e in droght, where it seems to us that the mark through the h might possibly be such an abbreviation. We have recorded the use of a five-line emphatic capital at the first word. We have prefaced each line with a line-marker, to allow a computer or a reader to find any given line.
We made the transcript by the simple process of a person sitting at the computer and typing the text onto the screen. In fact, we found it more efficient to begin with an existing transcript and to modify that. I am often asked whether it will ever be possible to use some kind of optical character reading system to read these manuscripts, and so save the labour of transcription. I do not believe this will ever be possible, for our transcription of these Middle English manuscripts at least. The most difficult decision we have to make is this: exactly which of the many marks on the page are significant, and should be transcribed? A competent Middle English scholar can look at the word droght in the second line and decide that the mark through the h might -- in this context -- be abbreviation, and so use a special character to transcribe the h. How could you teach a computer sufficient Middle English to make this decision?
The task of transcription is laborious, but has its own fascinations. We have found that for these texts we can reckon on a transcription rate of around 25 lines an hour. This figure includes carrying out at least three checks of the transcript. Where possible, the last of these checks is against the original. We believe that we are able to achieve an accuracy rate of less than one mistake every one hundred lines through this process. Our confidence in this appears to have been justified in the Wife of Bath's Prologue: in the two years since publication, we have been told of fewer than 10 errors in the 40,000 lines of transcription on the CD-ROM.
Collation
Once we have brought the transcripts to an acceptable level of accuracy, the next task is collation. For this we use the program Collate, running on Macintosh computers. Many features in this program have been specifically optimized for this work: in particular, it has powerful techniques for regularizing the text so that only significant variants are recorded. The object of our collation is to produce the most exact possible record of the agreements and disagreements among all the witnesses. For this purpose, we run the collation program across the text line by line. Here is the result of our collation of the word 'April' in the 34 witnesses which have the first line of the General Prologue:
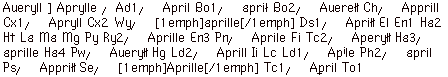
Figure 3: the collation in unregularized form
Regularization
This collation is accurate, and gives exactly the nineteen different spellings of this word in the 34 witnesses. But it is clear that most (perhaps all) of this variation is just variation in spelling, of no significance to the history of the text or to most modern readers. However, close scrutiny of these readings suggests that there appear to be two distinct and significant spellings underlying them all. One spelling is the spelling 'Aprill' which is how most modern editors render the word. The second is the spelling 'Aueryll'. We can use the regularization facility in Collate to reduce all these different spellings to just the two spellings: Aprill and Aueryll. Thus, running the collation again once we have done this regularization, the variants appear as follows:
![]()
Figure 4: the collation in regularized form
This gives a much clearer view of the variants at this point. It also suggests a rather fundamental break in the tradition, between the three manuscripts which have the spelling Aueryll and the 31 other manuscripts, which all have the spelling Aprill.
Here is a view of the computer tool we use to carry out the regularization process.

Figure 5: the interactive regularization process
In essence, we carry out the regularization by 'pointing and clicking': here, we click on the spelling Aueryll with the barred final consonant, and regularize it to Aueryll without the barred final consonant. Note that we can also assign the spelling to a lemma (here, Aueryll) and to a part of speech (here, noun singular). This allows us to build a very rich record of the spellings in all the manuscripts, sorted by headword form and part of speech.
This tool makes the task of collation and regularization very quick. It took about three months for two of us, working rather less than full-time, to collate and regularize every word in the 58 witnesses to the Wife of Bath's Prologue using this system.
The collation process creates an enormous quantity of information regarding the agreements and disagreements between the manuscripts. Analysis of this information may give us insight into the history of the tradition: what manuscripts were copied from what; what are the family relationships within the tradition; how the tradition developed. However, the sheer amount of information created by this collation process, with some 16,000 sets of variants in the General Prologue alone, will make manual analysis difficult. Accordingly, we turn to the computer again, to help us try to find a way through all this data.
Stemmatics and evolutionary biology
The stemmaticist who is analyzing the agreements and disagreements between manuscripts for evidence of relationship by descent, is doing the same thing as the evolutionary biologist who is analyzing the agreements and disagreements between species for evidence of relationship by descent. It is likely, then, that the same computer programs developed by evolutionary biologists for the reconstruction of trees of descent will also work in the analogous field of manuscript studies. Indeed, several experiments in this area have proved that, for some manuscript traditions at least, the methods developed in evolutionary biology give remarkably accurate results. Accordingly, we pass all the information generated by the collation to two different evolutionary programs. One of these, PAUP (for: Phylogenetic Analysis using Parsimony) is what one might call a classic cladistic program: it operates by testing the data against all possible trees in order to try and find the tree which best accounts for the variation within the tradition. The second, SPLITSTREE, uses a completely different technique. Rather than try and find the 'best tree', this program instead tries to estimate how 'treelike' the data is. Here is the view of the tradition of the General Prologue presented by SplitsTree for lines 0-250 in 21 manuscripts:
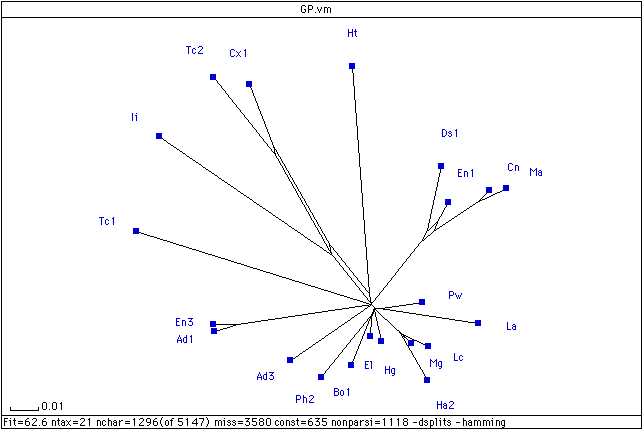
Figure 6: SplitsTree graph of lines 0-250 in 21 mss of the General Prologue
This view of the data suggests a fundamental cleavage in the tradition: between the witnesses in the top half of the table, from Ad3/Ad1/En3 around to the group Ds1/En1/Cn/Ma, and the witnesses in the bottom half of the table: from Ph2/Bo1 around to Pw/La. We call the first of these large groups the alpha group, the second the O group. Further, it suggests the existence of various other families within these two large alpha and O groupings: the four Ds1/EN1/Cn/Ma, the triplet Ii/Tc2/Cx1, with Ht perhaps linked to the root of these two families. The view of the data offered by PAUP is remarkably close to this:
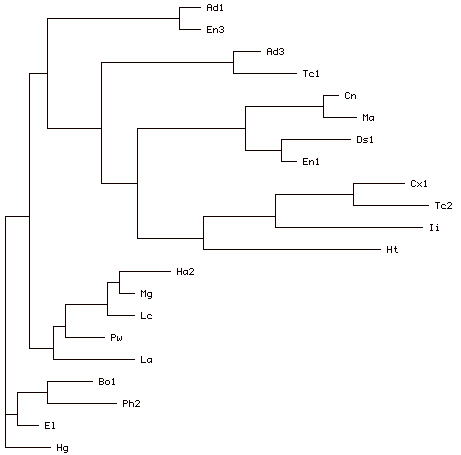
Figure 7: PAUP cladogram based on the same data as presented in Figure 6
We use these views of the relationships presented by these programs not as the end of analysis, but as its starting point. We have learnt to be suspicious of these programs: the results they give can be thrown off-course, sometimes wildly so, by data which a textual scholar would see at once is inconsequential. Thus, we use these programs to suggest relations which we then explore, confirm, clarify, extend -- or deny -- by other means.
Database analysis
The method we use to explore the tradition further is database analysis. The project version of Collate has built into it a very powerful database, specifically designed to give instant answers to the most complex queries. Here is an example of the kind of query we ask this database. Both the SplitsTree and PAUP views suggested that a major defining factor in the Canterbury Tales is the existence of a group of manuscripts descended from a single exemplar, which we have called the alpha exemplar. If there is such a group, and if there was such an exemplar, we will know it by the existence of a group of variants characteristically found in this group of manuscripts, and only in this group of manuscripts. These variants would therefore be likely to have been present in this hypothetical joint ancestor, and so might confirm its existence. This query is intended to isolate the readings which might have been introduced by this ancestor. If such a group of variants exist then they would probably be in at least 3 of the 'B' witnesses: the first line of the query. They would not usually be present in the other witnesses hypothesized as descending from the other node: that is the second line of the query. They would usually be in at least one of each of the pairs Cn Ma and En1 Ds1. Finally, perhaps most crucially, they would be in at least two of the witnesses Ad1 Ad3 Tc1 En3:

Figure 8: isolating the variants possibly present in the alpha ancestor
The variant database returned 34 variants as satisfying this query. And here, the human editor must make a judgement. Does this group of variants really represent evidence that all these manuscripts have a joint exemplar, which contained these variants? Or are we dealing with something else -- simple chance, for example. After all, there are some 7000 readings in any one manuscript of GP. The existence of a proportion of these 34 variants among the 7000 readings in any one manuscript may not be evidence of anything at all.
Our method is to isolate these groups of variants which appeared to have been introduced at a particular point in the tradition: in this case, by the alpha exemplar. We then use the 'variant group profile' facility in Collate to count how many of the variants in any given group are present in any one manuscript. Suppose that a manuscript has (say) 25 of these 34 alpha variants. We might then reasonably suppose that so high a proportion is unlikely to be chance, and that this manuscript is descended from alpha. In fact, Ad1 had 25 of these; Tc1 24; En3 28. We can use the same system to determine contamination and shift of exemplars. For contamination, a manuscript will combine readings from two groups; in cases of shift of exemplar, the manuscript will move at a particular point from one group to another.
The next stage of our work is publication. Because all our material is in electronic form, and because of the sheer quantity of it, publication must be in electronic form. We published the first CD-ROM, of the Wife of Bath's Prologue, in June 1996; our second CD-ROM, of the General Prologue, will be published early in 2000. These CD-ROMs present transcripts and images of all the text in all the witnesses, as can be seen in this image and transcript of the first lines of the Fitzwilliam manuscript:
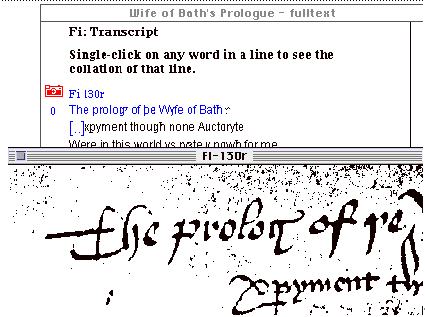
Figure 9: transcripts and images of the Fitzwilliam manuscript
They also present a complete word by word collation of the text, as in this example (for the first word of the Wife of Bath's Prologue)

Figure 10: presentation of the regularized collation on the CD-ROM
We include much else on each CD-ROM: descriptions of each witness (done by Dan Mosser), transcripts of the glosses (from Stephen Partridge); articles by members or associates of the project. Perhaps the most unusual feature of the CD-ROMs are the spelling databases. In these, we give every spelling of every manuscript form, classified by headword and part of speech. Here is the beginning of the entry for the verb 'to be' in the spelling database:

Figure 11: the spelling database
The entry for 'be' is divided into some thirty different parts of speech, with all the spellings for each part of speech in all the witnesses grouped together. Hypertext links take the reader to the single-witness spelling database for a given witness, or to the text of all occurrences of this spelling in a particular witness, and from there to the transcription of the witness itself.
All of what I have described is present on the Wife of Bath's Prologue CD-ROM. As well as all this, we plan to include on the General Prologue CD-ROM a tool for stemmatic analysis (SplitsTree) and the variant database. We will also include instructions for their use, and some samples of how we have used them. Readers will then be able to use these to carry out their own analysis.
We began this work with the intention of trying to create a better reading text of The Canterbury Tales. As the work has proceeded, our aims have changed. Rather than trying to create a better reading text, we now see our aim as helping readers to read these many texts. Thus, from what we provide, readers can read the transcripts, examine the manuscripts behind the transcripts, see what different readings are available at any one word, and determine the significance of a particular reading occurring in a particular group of manuscripts. Perhaps this aim is less grand than making a 'definitive' text; but it may also be more useful.
Next steps
In early 1999, the Project (after some ten years of hand-to-mouth existence) received secure medium-term funding, until 2004, from the Arts and Humanities Research Board. With this funding, we are now able to plan and achieve a publication schedule over the five years from 1999 to 2004. Our aim is to produce the equivalent of ten CD-ROMs in this period. The first of these will be Elizabeth Solopova's edition of The General Prologue, to be published in early 2000. This will be followed by Lorna Stevenson's edition of The Miller's Tale. We plan to follow this by a series of 'single-manuscript' CD-ROMs, presenting a full set of digital images of all pages in the manuscript, a full transcript of the text of the manuscript, a description, and a variety of other materials. These latter publications will require the full co-operation of the libraries which own the manuscripts, and we are at an advanced stage of negotiation with these libraries. We hope to publish the first of these 'single-manuscript' CD-ROMs in 2000.
We are also actively exploring the option of internet publication. Our first CD-ROMs (the Wife of Bath, and forthcoming General Prologue and Miller's Tale) all use DynaText software, from Electronic Book Technologies (now part of Inso Corporation). This software is now rather old (in computing terms), is not adequate to the increasing complexity of our publications, and (especially) cannot run over the internet. We believe that publications of this type should be available with an identical interface for CD-ROM and the internet. Therefore we are developing, with the Centre for Technology and the Arts, a suite of software tools which will permit very complex and large SGML-based publications such as ours to be distributed in identical form over the web and on CD-ROM.